
[ad_1]
Machine learning is transforming fraud detection by swiftly identifying unusual patterns in data, helping prevent financial losses and safeguarding against identity theft and unauthorized transactions.
Fraud detection is vital for many businesses and organizations, especially in the financial sector. According to a report by PwC, the global cost of fraud in 2020 was estimated at $42 billion.
Therefore, it is essential to have efficient methods and tools — anti-spy programs, etc., to detect and prevent fraud.
One of the most promising tools for fraud detection is machine learning — technology that implies data-based training for predictions or decisions. This technology can:
- Analyze large and complex data sets
- Identify patterns and anomalies
- Adapt to changing behaviours and scenarios
- Provide insights into the causes and factors of fraud, as well as recommendations and solutions to combat it
In this article, we will explore how machine learning is used in fraud detection, its benefits and challenges, and some best practices on the example of the fraud detection website.
How does machine learning work for fraud detection?
Machine learning works by creating and applying algorithms that can learn from data without being explicitly programmed. These algorithms can be classified into two main categories:
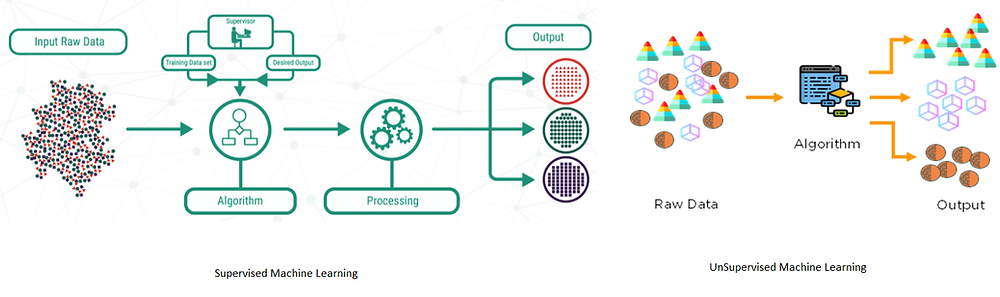
- Supervised learning. Here, algorithms learn from a set of labelled data: every data point has a known outcome or class. For example, it can be trained on a set of credit card transactions that are labelled as either fraudulent or legitimate and learn to identify features that can identify fraudulent and legitimate transactions.
- Unsupervised learning. This involves training on unlabeled data. It means there is no known outcome or class for each data point. For example, an unsupervised learning algorithm can learn from a set of credit card transactions without knowing which ones are fraudulent or legitimate. As a result, it can detect outliers or anomalies among the transactions and indicate potential fraud.
What are the benefits of machine learning for fraud detection?
Machine learning offers many benefits for fraud detection, such as:
- Scalability: Machine learning can proceed with big data sets containing noise, missing values, or irrelevant features. It can also process data in real-time or near real-time, which is crucial for fraud detection.
- Adaptability: Machine learning adapts to changing patterns of fraudsters by continuously learning from new data. Besides, it handles dynamic or evolving fraud scenarios, such as new types of fraud, new channels of fraud, or new targets of fraud.
- Insightfulness: Machine learning can provide insights into the underlying causes or factors of fraud by identifying important features. Also, you can get recommendations or solutions to prevent or mitigate fraud by suggesting actions or policies.
What are the challenges of machine learning for fraud detection?
Machine learning also faces some challenges or limitations for fraud detection. Here are the most common ones.
Data quality
Machine learning depends on the data quality used to train and test the algorithms. Poor data quality can lead to inaccurate or unreliable results:
- Incomplete data. If data is missing some important features or variables, the algorithms may not be able to capture the full picture or context of the problem.
- Incorrect data. Data with errors or outliers might result in algorithms learning from false or misleading information.
- Inconsistent data. Data with duplicates or conflicts might confuse the algorithms with contradictory information.
- Irrelevant data. With data that is irrelevant or contains noise or redundant variables, the algorithms may be distracted or overwhelmed by unnecessary information.
Possible solutions to improve data quality:
- Data cleaning and preprocessing to remove errors, duplicates, conflicts, noise, etc.
- Data imputation and interpolation to fill in missing gaps.
- Data transformation and normalization to standardize or scale the data into a common format or range.
- Data augmentation and synthesis to generate new or additional data from existing data.
Data imbalance
Data balance refers to the distribution or proportion of the classes or outcomes in the data. Imbalanced data can lead to skewed or biased results. To address data imbalance, some possible steps are:
- Data resampling and rebalancing to adjust the distribution or proportion of the classes or outcomes in the data.
- Data stratification and cross-validation to ensure that each fold or subset of the data contains a representative sample of each class or outcome in the data.
Data privacy
Data privacy is about the protection or security of the personal or sensitive information in the data — and it can pose ethical or legal issues for machine learning. For example, suppose the data contains personal or sensitive information about users, such as name, address, phone number, email, credit card number, etc.
In that case, the algorithms may violate their privacy or expose them to identity theft or other risks. This can result in a loss of trust or reputation for the organization.
To protect data privacy, some possible steps are:
- Data encryption and decryption to convert plain text into cypher text and vice versa using a secret key.
- Data anonymization and pseudonymization to remove or replace personal or sensitive information from the data with random or fictitious values.
- Data aggregation and generalization to reduce the granularity or specificity of the data by grouping or summarizing it into higher-level categories or ranges.
Machine learning for fraud detection in action: case studies and best practices
Machine learning for fraud detection is not a one-size-fits-all solution. It requires careful planning, design, implementation, evaluation, and maintenance.
Some of the best practices and examples of machine learning for fraud detection are:
- Define a specific problem and objective for fraud detection. For example, what type of fraud do you want to detect? What are the criteria or indicators of fraud? What are the expected outcomes or benefits of fraud detection?
- Choose an appropriate machine learning technique and model for fraud detection. For example, what kind of data do you have? What kind of features or variables do you need? What kind of performance or accuracy do you want?
- Collect and prepare high-quality data for fraud detection. For example, where do you get your data from? How do you clean data?
- Train and test your machine learning algorithm for fraud detection. For example, how do you set up your algorithm parameters? How do you measure your algorithm performance and validate its results?
- Deploy and monitor your machine learning solution for fraud detection. For example, how do you integrate your solution with your existing system? How do you update your solution with new data?
Let’s look at some examples of machine learning applications on the example of a fraud detection website that uses machine learning models:
- to analyze credit card transactions and flag suspicious ones based on their features, such as amount, location, time, frequency, etc.
- to verify the identity and behaviour of online shoppers and prevent fraudulent transactions based on their features, such as device, IP address, email, phone number, etc.
- to analyze healthcare claims and detect anomalies or patterns that indicate fraud based on their features, such as provider, service, amount, diagnosis, etc.
Conclusion
Machine learning is a powerful fraud detection tool. However, it faces some challenges or limitations for fraud detection — and thus, it is important to follow some best practices and examples to avoid the issues.
RELATED TOPICS
[ad_2]
Source link